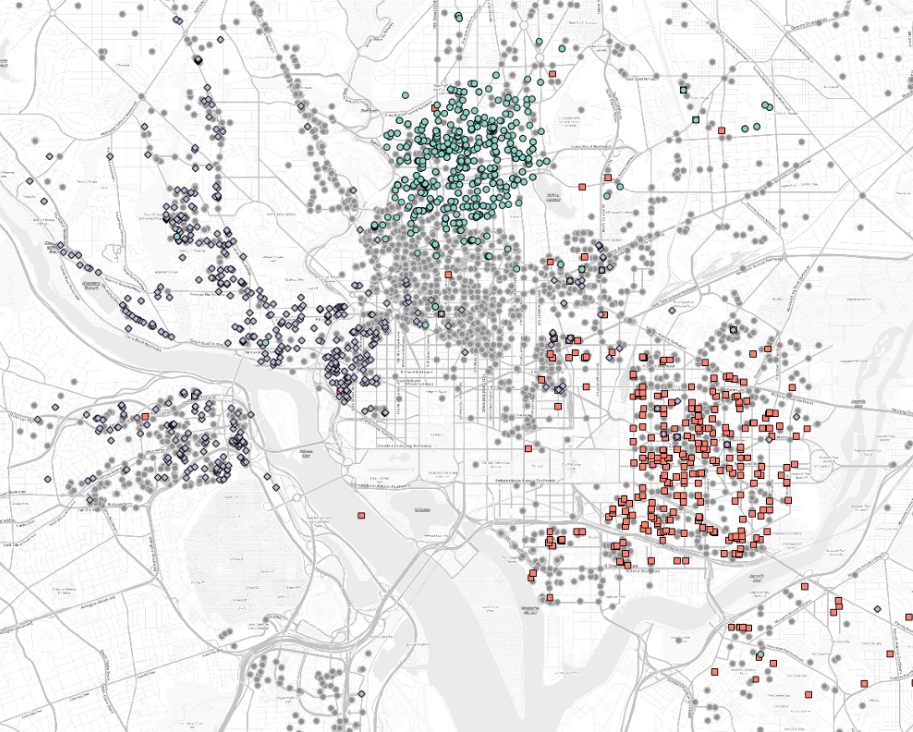
In 2014, Google published a neighborhood map of Brooklyn, the most populous borough in New York City, a seemingly harmless step in providing its users with useful geographic boundary information. The backlash was swift. Residents of Brooklyn responded angrily, many stating that a commercial company such as Google had no right to label and define boundaries within their city. This was not a lone incident, as many mapping agencies, both government and commercial, have come to realize that regional boundaries and names are a contentious issue. Google and others are frequently placed in the difficult situation of publishing hard boundaries and definitive names for regions that are in dispute or poorly defined, often applying names to parts of the city that few residents have even heard before. This poses a problem as the names assigned to neighborhoods are important for understanding one’s identity and role within an urban setting. Names provide a bond between a citizen and a place. In many cases neighborhood names are much more than just a set of characters, they have a history that is situated in religious beliefs, gender identity, and/or race. Neighborhood names evolve over time and are given meaning by the neighborhood’s inhabitants. Applying a top-down approach to naming neighborhoods, a practice often done by municipalities and commercial agencies, can produces unforeseen, even anger-inducing, results. In our recently published open access paper in the ISPRS International Journal of Geo-Information, we explore this topic and propose an ensemble learning / spatial statistics approach to identifying neighborhood names.